Robots.txt nedir? Ne İşe Yarar?
Robots.txt, web sitelerinin sayfalarının nasıl taranacağını arama motorlarına açıklamak amacıyla oluşturulmuş metin dosyalarıdır. Robots.txt dosyası, REP’in (robot dışlama protokolü) bir parçasıdır. REP, robotların web sitenizi nasıl taradığını, içeriğinize nasıl erişilebileceğini ve içeriklerinizin dizine nasıl eklenebileceğini belirleyen bir grup web standardı olarak tanımlanabilir. Ayrıca REP, meta robotlar gibi talimatların dışında, motorların bağlantılara karşı nasıl davranması gerektiğiyle ilgili sayfa, alt dizin ya da site bütünü hakkında talimatlar da içerir. (Takip et, takibi bırak gibi)
Robots.txt dosyaları uygulamada, belirli web tarama yazılımlarının bir web sitesinin hangi bölümlerini tarayabileceğini ya da tarayamayacağını belirtir. Bu talimatlar“allowing” ya da “disallowing” şeklinde belirtilir.
Temel format:
User-agent: [İlgili web tarayıcılarının listesidir.]
Disallow: [URL dizesi taranmamalı.]
Bir robot dosyasında birden fazla kullanıcı yönergesi bulunabilir. [Disallow, allow, crawl-delays(tarama gecikmesi) gibi.] Yukarıdaki 2 satır birlikte tam bir robots.txt dosyası olarak kabul edilir.
Bir robots.txt dosyasında her bir user-agent yönergesi için ayrık iki küme görüntülenir:
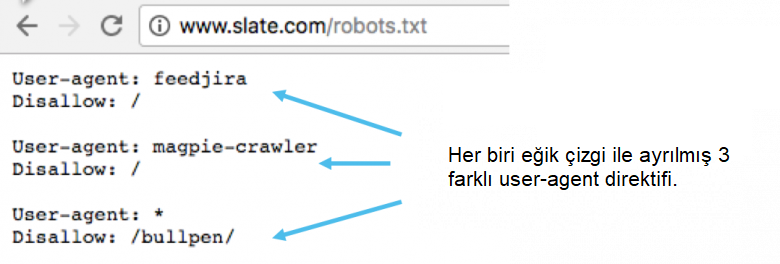
Birden fazla user-agent yönergesine sahip olan robots.txt dosyalarında, her bir allow ya da disallow kuralı sadece bulunduğu satırda yer alan kullanıcılar için geçerlidir. Dosya birden fazla user-agent kuralı içeriyorsa tarayıcı sadece en spesifik olan talimat grubunu dikkate alır.
İşte bir örnek:
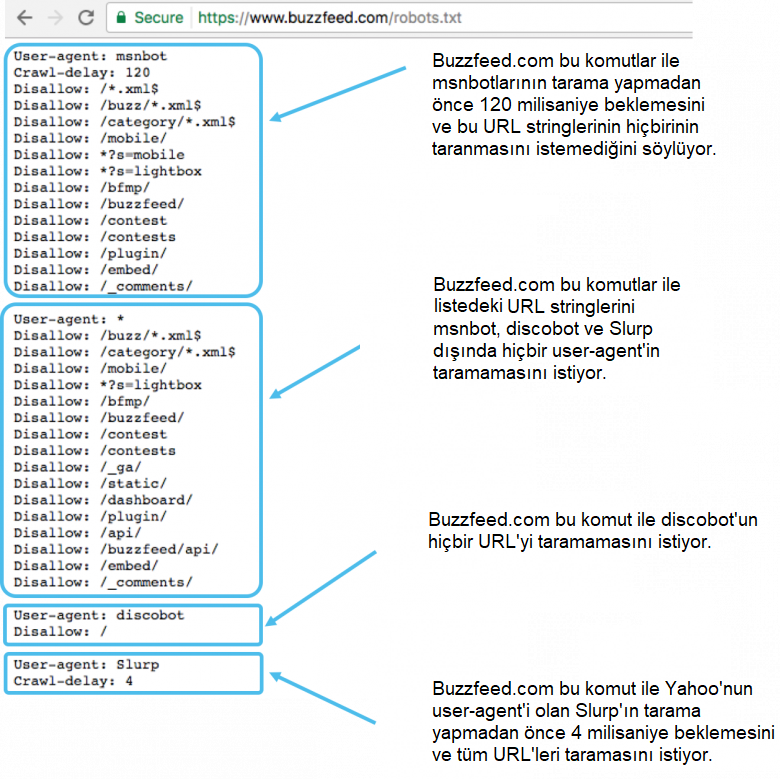
Msnbot, discobot ve Slurp özel olarak çağırılır, bu yüzden user-agentler sadece robots.txt dosyasının belirli bölümlerindeki kurallara dikkat etmelidir. Diğer tüm user-agentler de user-agent: *grubundaki kuralları izleyecektir.
Örnek robots.txt:
Hayali bir www.ornek.com web sitesi için oluşturulan robots.txt uygulamasına birkaç örnek verelim:
Robots.txt dosyasının URL’si: www.ornek.com/robors.txt
Tüm tarayıcılar için tüm içerikleri engellemek için:
User-agent: *
Disallow: /
Bu komutları robots.txt dosyasında kullanmanız, tüm web tarayıcılarına www.ornek.com‘daki ana sayfa dahil tüm sayaları taramamasını söyler.
Tüm web tarayıcıların tüm içeriklere erişmesine izin vermek için:
User-agent: *
Disallow:
Bu dizinleri robots.txt dosyasında kullanmanız, tüm web tarayıcılarına www.ornek.com‘daki tüm sayfaları taramalarını söyler.
Belirli web tarayıcılarına belirli klasörleri engelleme:
User-agent: Googlebot
Disallow: /ornek-subfolder/
Bunu robots.txt dosyasına eklediğiniz zaman Google’ın tarayıcısına (Googlebot) www.ornek.com/ornek-subfolder/URL’sindeki sayfaları taramayacağını bildirirsiniz.
Belirli bir tarayıcıya belirli bir sayfayı engelleme
User-agent: Bingbot
Disallow: /ornek-subfolder/engellenen-sayfa.html
Bunu kullanarak Bing’in tarayıcısı olan Bingbot’a www.ornek.com/ornek-subfolder/engellenen-sayfaadresindeki sayfayı taramayacağını bildirirsiniz.
Robots.txt nasıl çalışır?
Arama motorlarının iki ana görevi vardır:
İçerikleri keşfetmek için web’i tararlar.
İçerikleri, araştırma yapan kişilerin hizmetlerine sunabilmek için dizine eklerler.
Arama motorları site site gezerek milyarlarca siteye ulaşır ve tarama yapar. Bu tarama işlemlerini yapan tarayıcılara “örümcek” de denir.
Bir web sitesine girildiği zaman örümcekler taramaya başlamadan önce bir robots.txt dosyası ararlar. Bir robots.txt bulurlarsa tarayıcı sayfayı taramadan önce dosyayı okuyacaktır. Robots.txt dosyaları, arama motorlarına nasıl tarama yapmaları gerektiğini söyleyeceği için tarayıcılar daha fazla gereksiz tarama işleminde bulunmayacaklarını anlayacaktır. Eğer bir sitede bir robots.txt dosyası yoksa ya da var olan robots.txt dosyası herhangi bir kısıtlama kuralı içermiyorsa tarayıcı sitedeki tüm sayfaları taramaya devam edecektir.
Robots.txt hakkında bilinmesi gerekenler(daha aşağıda ayrıntılı anlatacağız):
Bulunabilmek için bir web sitesinin üst düzey dizinine bir robots.txt dosyası yerleştirilmelidir.
Robots.txt, küçük ve büyük harflere duyarlıdır: dosyanızın adını “robots.txt” yapmalısınız. (Robots.txt, robots.TXTya da herhangi farklı bir şey değil.)
Bazı user agentler(robotlar) robots.txt dosyanızı görmezden gelebilir. Bunu genellikle kötü niyetli robotlar ya da e-posta hırsızları gibi zararlı tarayıcılar yapar.
/robots.txt dosyası genel kullanıma sunulmaktadır: Bir web sitesinin kurallarını görmek için herhangi bir kök domain adının sonuna /robots.txt eklemelisiniz. Eğer bir robots.txt dosyası varsa karşınıza çıkacaktır. Bu ilgili sayfaları herkesin görebileceği fakat bu sayfaların taranmayacağı anlamına gelmektedir. Yani özel kullanıcı bilgilerinizi bu şekilde gizleyemezsiniz.
Bir kök domain adının altında yer alan her subdomain, ayrı bir robots.txt dosyasını kullanır. Yani hemblog.ornek.com hem de ornek.com‘un kendisi ayrı ayrı birer robots.txt dosyasına sahip olmalıdır. (blog.ornek.com/robots.txt ve ornek.com/robots.txt)
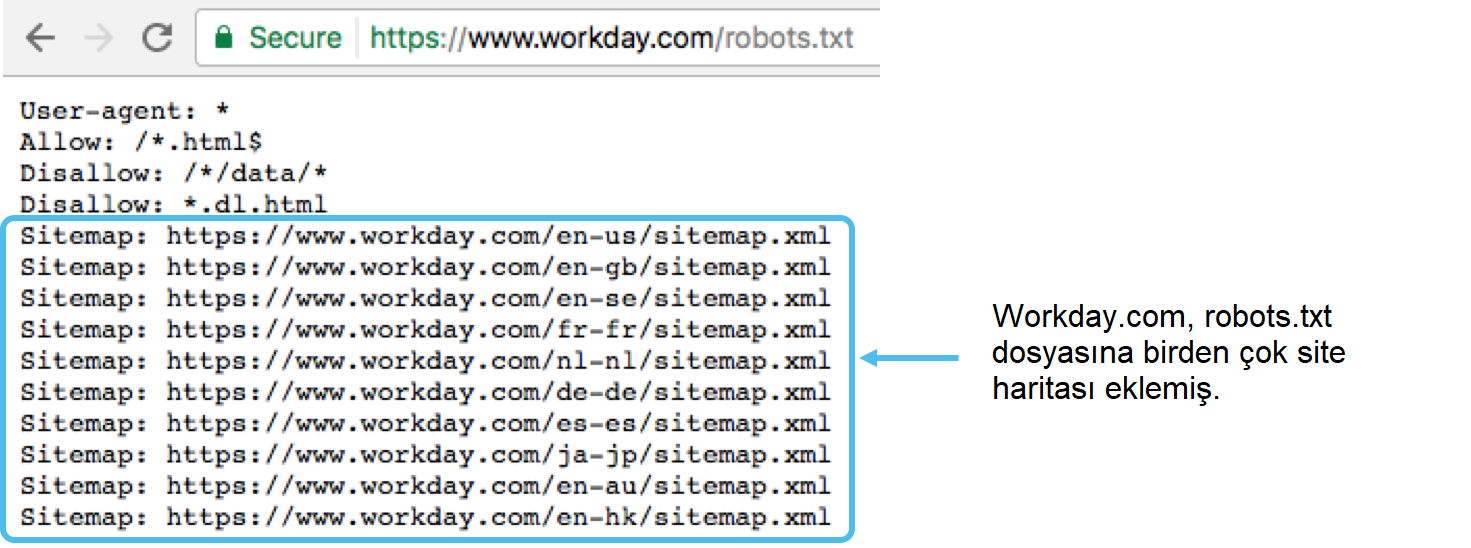
Domain adıyla ilişkili herhangi bir sitemap‘in yerini robots.txt dosyasının alt kısmında açıklamak genelde en iyi uygulamalardan bir tanesidir. İşte bir örnek:
Robots.txt sözdizimi
Robots.txt sözdizimi, bir robots.txt dosyasının “dili” olarak tanımlanabilir. Bir robots.txt dosyasında karşınıza çıkması muhtemel 5 terim vardır. İşte o terimler:
User-agent: Tarama talimatları verdiğiniz belirli web tarayıcılarını ifade eder. Bunlar genellikle arama motorlarıdır.
Disallow: Belirli bir URL’nin taranmamasını söyleyen komuttur. Her URL için sadece bir “Disallow” satırına izin verilir.
Allow (Sadece Googlebot için geçerlidir): Googlebot’a izin verilmese bile bir sayfaya ya da alt klasöre erişebileceğini söyleyen komuttur.
Crawl-delay: Tarayıcıya, sayfa içeriğini yüklemeden ve taramadan önce birkaç milisaniye beklemesini söyleyen komuttur. Googlebot bu komutu onaylamaz, fakat tarama hızını ayarlamak için Google Search Console’u kullanabilirsiniz.
Sitemap: URL ile ilgili herhangi bir XML site haritasının bulunduğu yeri çağırmak için kullanılır. Bu komutu sadece Google, Ask, Bing ve Yahoo desteklemektedir.
Pattern-matching (model eşleştirme)
Engellenecek olan ve izin verilecek olan URL’ler söz konusu olduğu zaman ve üzerine bir de model eşleştirme kuralı eklendiği zaman robots.txt dosyaları oldukça karmaşık bir hale geliyor.
Google ve Bing, bir SEO tarafından dışlanmak istenen sayfalar ya da subdomainler için kullanabileceğiniz 2 ifadeyi de onaylıyor. Bu ifadeler; yıldız (*) ve dolar ($) işaretidir.
Robots.txt bir sitenin neresinde bulunur?
Bir web sitesine girildiği zaman arama motorları ve Facebot (Facebook’un tarayıcısı) gibi diğer web tarama motorları robots.txt dosyasının nerede bulunduğunu bilirler. Robots.txt dosyanızı ararken belirli bir yeri incelerler: ana dizin; genellikle kök domaininiz ya da ana sayfanız. Eğer bir araçwww.ornek.com/robots.txt adresini ziyaret edip de orada bir robots.txt dosyası bulamazsa, sitede bir robots.txt dosyasının var olmadığını ve sitenin tamamını taramaya devam edeceğini kabul edilir. Hatta robots.txt dosyanızornek.com/index/robots.txt‘de ya dawww.ornek.com/homepage/robots.txt‘de var olsa bile araçlar tarafından bulunamayacağı için sitedeki her şey hiç robots.txt dosyası yokmuş gibi ele alınacaktır.
Robots.txt dosyanızın bulunmasını istiyorsanız mutlaka ana dizininize ya da kök domaininize eklemelisiniz.
Neden bir robots.txt dosyasına ihtiyacınız var?
Robots.txt dosyaları sitenizin belirli kısımlarına yönelik olan tarayıcı erişimlerini düzenler. Googlebot’un sitenizi taramasına yanlışıkla izin vermezseniz bu durum çok olumsuz sonuçlar doğurabilir. Bir robots.txt dosyasının çok kullanışlı olabileceği zamanlar da mevcut:
Kopya içeriğin SERP’lerde görünmesini önleyebilirsiniz. Bunun için meta robotlar daha iyi bir seçimdir.
Web sitenizin belirli bölümlerini gizli tutabilirsiniz.
Dahili arama sonuçları sayfalarını kamuya açık SERP’lerde gösterilmesini engelleyebilirsiniz
Site haritalarının konumlarını belirtebilirsiniz.
Arama motorlarının web sitenizde yer alan belirli dosyaları endekslemesini engelleyebilirsiniz.
Tarayıcılar aynı anda birden fazla içerik yükleyerek sunucularınızda aşırı yüklenmelere sebep olabilir ve bunu önlemek için bir tarama gecikmesi oluşturabilirsiniz.
Robots.txt dosyanız olup olmadığını kontrol etme
Bir robots.txt dosyanızın olup olmadığından emin değil misiniz? Kök domain adınızı yazın ve ardından URL’nizin sonuna /robots.txt yazarak bir robots.txt dosyanızın olup olmadığını kolaylıkla öğrenebilirsiniz. Örneğin;ornek.com/robots.txt
Bu işlemin sonunca karşınıza bir .txt dosyası gelmezse, bu aktif bir robots.txt dosyanızın olmadığı anlamına gelir.
En iyi SEO uygulamaları
Web sitenizde taranmasını istediğiniz herhangi bir içeriğin ya da sayfanın engellenmediğinden emin olun.
Robots.txt tarafından engellenen sayfalar ve bu sayfalardaki bağlantılar taranmayacaktır. Böylelikle mevcut sayfalardaki bağlantılar ve kaynaklar taranamayacağı için dizine eklenemez. Eğer sayfa içeriğindeki bağlantılara erişim olmasını istiyorsanız farklı bir engelleme sistemi kullanmalısınız.
Hassas veriler gibi özel kullanıcı bilgilerinin SERP’lerde (arama motoru sonuç sayfaları) görünmesini istemiyorsanız robots.txt kullanamayın. Diğer sayfalar doğrudan özel bilgilerinizi içeren sayfalara bağlanabilir bu yüzden bu sayfaların dizine eklenmesi de mümkündür. Bu tarz bir sayfanızı arama motorları sonuçlarında görmek istemiyorsanız parola koruması yapabilir ya da noindex meta yönergesi gibi daha farklı bir yöntemi kullanabilirsiniz.
Bazı arama motorlarının birden fazla tarama aracı vardır. Örneğin Google, organik aramalar için Googlebot’u görüntü aramaları için de Googlebot-Image’yi kullanıyor. Bu tarama araçlarından bir tanesini engellediğiniz zaman arama motorları zaten aynı kuralı diğer araç için de uygulayacaktır. Fakat siz yine de 2 aracı da engelleyebilecek ince ayar yapabilecek beceriye sahip olmalısınız.
Bir arama motoru, robots.txt içeriğini kendi önbelleğine alır, fakat genellikle önbelleğe alınmış olan içeriği günde en az 1 kez günceller. Eğer dosyada değişim yaparsanız ve arama motorundan daha hızlı bir güncelleme isterseniz robots.txt dosyanızı Google’a gönderebilirsiniz.
Robots.txt vs meta robotlar vs x-robotlar
Görüldüğü üzere birçok robot mevcut. Peki bu robotlar arasındaki farklar nedir? Hangisi sizin için daha uygun? Öncelikle; robots.txt gerçek bir metin dosyasıdır. Meta ve x-robotları ise meta yönergeleridir. Aslında teknik olarak bu robotların 3’ü de farklı amaçlara hizmet eder. Robots.txt dosyası site ve dizin çapındaki tarama davranışlarını belirliyorken, meta robotları ve x-robotları da sayfa düzeyinde işlemler için uygundur.

Yorumlar
Yorum Gönder